

Seuraat nyt käyttäjää
Virhe seurattaessa käyttäjää.
Tämä käyttäjä ei salli käyttäjien seurata häntä.
Seuraat jo tätä käyttäjää.
Jäsenyystasosi mahdollistaa vain 0 seurausta. Päivitä tästä.
Käyttäjän seuraaminen lopetettu onnistuneesti
Virhe poistettaessa käyttäjän seurantaa.
Olet onnistuneesti suositellut käyttäjää
Virhe suositeltaessa käyttäjää.
Jokin meni vikaan. Päivitä sivu ja yritä uudelleen.
Sähköposti vahvistettu onnistuneesti.

saharanpur,
india
Aika on tällä hetkellä 8:38 ap. täällä
Liittynyt marraskuuta 4, 2012
3
Suosittelee
Mohd T.
@tausy
6,4
6,4
97%
97%
saharanpur,
india
96 %
Suoritetut työt
83 %
Budjetin mukaisesti
95 %
Aikataulussa
17 %
Uudelleenpalkkausaste
ML, AI, Data Science, Python, Hadoop, Databases
Ota yhteyttä käyttäjään Mohd T. työhösi liittyen
Kirjaudu sisään keskustellaksesi yksityiskohdista chatissa.
Portfolio
Portfolio

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark


Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning


Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment


FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING


Animals Image Classification Using Deep/Transfer Learning

Animals Image Classification Using Deep/Transfer Learning

Animals Image Classification Using Deep/Transfer Learning

Animals Image Classification Using Deep/Transfer Learning
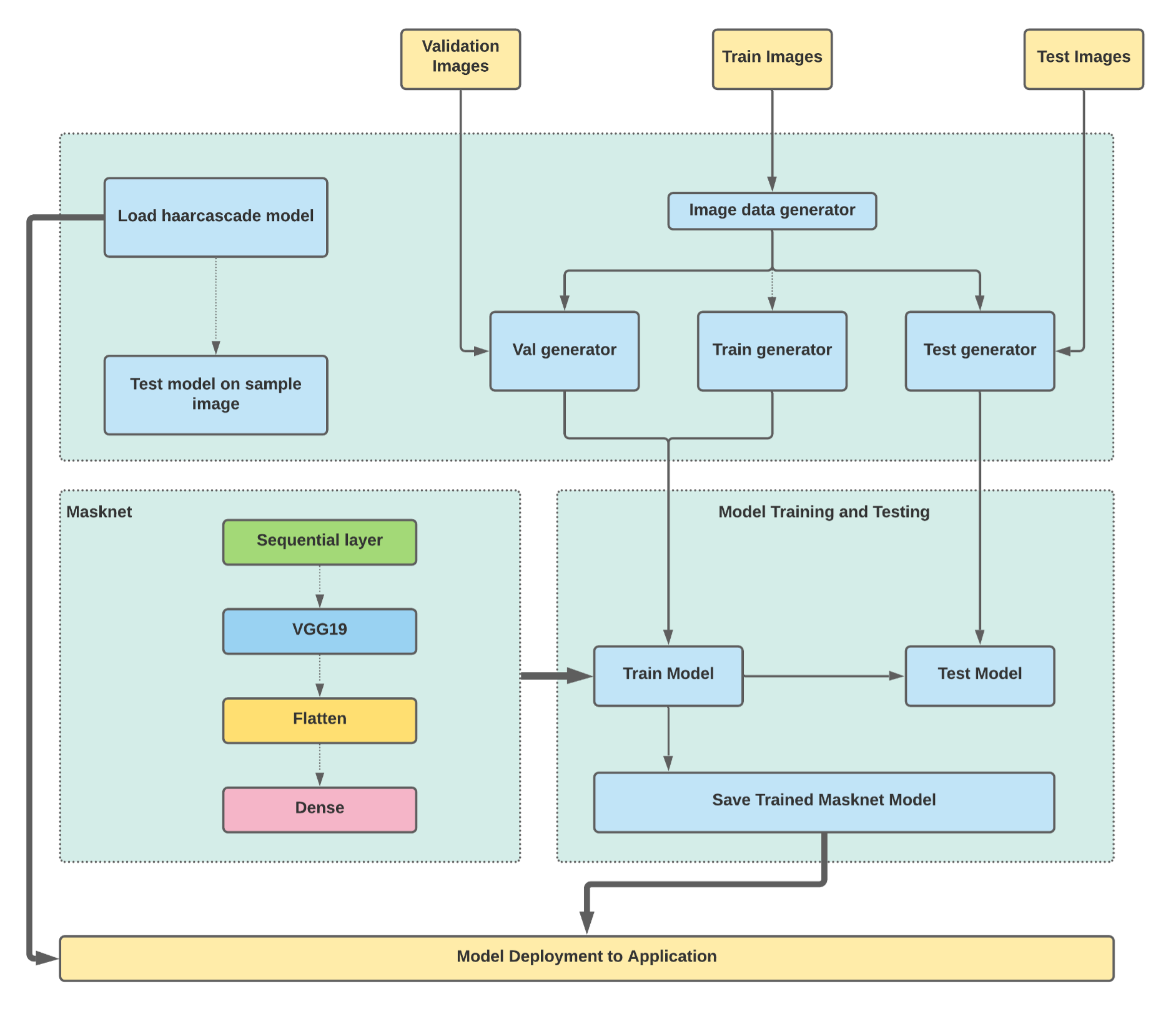

Mask Detection/Real-time Human Counting with Deep Learning

Mask Detection/Real-time Human Counting with Deep Learning

Mask Detection/Real-time Human Counting with Deep Learning
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
Animals Image Classification Using Deep/Transfer Learning
Animals Image Classification Using Deep/Transfer Learning
Animals Image Classification Using Deep/Transfer Learning
Animals Image Classification Using Deep/Transfer Learning
Mask Detection/Real-time Human Counting with Deep Learning
Mask Detection/Real-time Human Counting with Deep Learning
Mask Detection/Real-time Human Counting with Deep Learning
Arvostelut
Muutokset tallennettu
Näytetään 1 - 5 / 50+ arvostelua
₹16 000,00 INR
Python
Machine Learning (ML)
S
•
₹20 000,00 INR
Python
Data Processing
Excel
Microsoft Access
MySQL
•
$120,00 USD
Java
Python
Machine Learning (ML)
Big Data Sales
+1 enemmän

•
$350,00 SGD
Python
Software Architecture
Report Writing
Machine Learning (ML)
Statistical Analysis

•
Kokemus
Hadoop/Machine Learning Developer
syysk. 2017 - Voimassa
Working on Hadoop Ecosystem in combination with python/machine learning to deliver predictive models.
Data Scientist
jouluk. 2019 - Voimassa
Working as a data scientist in AI/ML team.
Hadoop Developer
huhtik. 2016 - elok. 2017 (1 , 4 kuukautta)
Worked on Hadoop ecosystem to deliver cutting edge predictive models using Sqoop, Flume, Oozie, Hive, Map Reduce
Koulutus
MSc Data Science
(1 )
Bachelor Of Technology (Computer Engineering)
(4 vuotta)
Pätevyydet
Certificate in Healthcare
Tata Business Domain Academy
2014
Oracle Database Certified SQL Expert
Oracle University
2015
SQL proficiency test certificate provided by Oracle
Oracle Database Certified PL/SQL Expert
Oracle University
2015
Pl/SQL proficiency test certificate provided by Oracle
Ota yhteyttä käyttäjään Mohd T. työhösi liittyen
Kirjaudu sisään keskustellaksesi yksityiskohdista chatissa.
Varmennukset
Todistukset
Selaa vastaavia freelancereita
Selaa vastaavia näyteikkunoita
Kutsu lähetetty onnistuneesti!
Kiitos! Olemme lähettäneet sinulle sähköpostitse linkin, jolla voit lunastaa ilmaisen krediittisi.
Jotain meni pieleen lähetettäessä sähköpostiasi. Yritä uudelleen.
Kopiointi leikepöydälle epäonnistui. Yritä uudelleen, kun olet muuttanut käyttöoikeuksiasi.
Kopioitu leikepöydälle.
Ladataan esikatselua
Lupa myönnetty Geolocation.
Kirjautumisistuntosi on vanhentunut ja sinut on kirjattu ulos. Kirjaudu uudelleen sisään.